Tutorial 2: Introduction to Pandas
A tutorial of some commonly used function in Pandas



 Estimated time: 15 minutes
Estimated time: 15 minutes
Pandas
pandasis derived from the term "panel data", an econometrics term for data sets that include observations over multiple time periods for the same individuals. — Wikipedia
The pandas package is the most important tool at the disposal of Data Scientists and Analysts working in Python today. Through pandas, you get acquainted with your data by cleaning, transforming, and analyzing it.
Simply, pandas can do anything you could imagine of with data.
DataFrame and Series
The primary two components of pandas are the Series and DataFrame. A Series is essentially a column, and a DataFrame is a multi-dimensional table made up of a collection of Series.
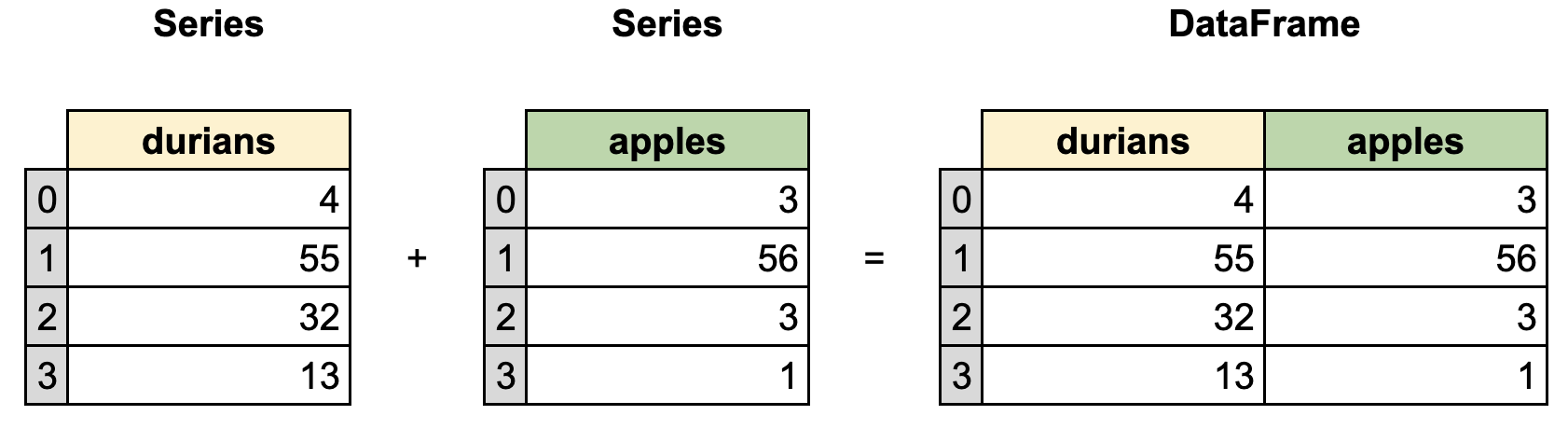
DataFrames and Series are quite similar in that many operations that you can do with one you can do with the other, such as filling in null values and calculating the mean.
Creating dataframe
import pandas as pd
data = {
'durians': [4, 55, 32, 13],
'apples': [3, 56, 3, 1]
}
fruit = pd.DataFrame(data)
fruit
Each item (key, value) in data corresponds to a column in the resulting DataFrame.
The Index of this DataFrame was given to us on creation as the numbers 0-3, but we could also create our own when we initialize the DataFrame.
Let's put customer names as our index:
fruit = pd.DataFrame(data, index=['Ali', 'Abu', 'Lim', 'Muthu'])
fruit
fruit.loc['Ali']
!wget http://gg.gg/fruit-csv -O fruit.csv
df = pd.read_csv('fruit.csv')
df
CSV doesn't have indexes like DataFrames. So, we need to designate the index_col when reading.
df = pd.read_csv('fruit.csv',index_col=0)
df
The same goes for reading JSON, SQL, Excel file, etc. Basically you could read anything. Read more from the documentation here
df.to_json('fruit.json')
In Linux system, you could read a file contant through cat command.
!cat fruit.json
!wget http://gg.gg/cov-1 -O covid19.csv
covid = pd.read_csv('covid19.csv')
covid.head()
covid.tail()
Typically when we load in a dataset, we like to view the first five or so rows to see what's under the hood. Here we can see the names of each column, the index, and examples of values in each row.
Getting info about the data
.info() should be one of the very first commands you run after loading your data:
covid.info()
.info() provides the essential details about your dataset, such as the number of rows and columns, the number of non-null values, what type of data is in each column, and how much memory your DataFrame is using.
Shape of the data
Another fast and useful attribute is .shape, which outputs just a tuple of (rows, columns):
covid.shape
covid_tmp = covid.append(covid)
covid_tmp.shape
Using append() will return a copy without affecting the original DataFrame. Now, let's drop the duplicates.
covid_tmp = covid.drop_duplicates()
covid_tmp.shape
It's a little verbose to keep assigning DataFrames to the same variable like in this example. For this reason, pandas has the inplace keyword argument on many of its methods. Using inplace=True will modify the DataFrame object in place. Another important argument for drop_duplicates() is keep, which has three possible options:
-
first: (default) Drop duplicates except for the first occurrence. -
last: Drop duplicates except for the last occurrence. -
False: Drop all duplicates.
covid_tmp.drop_duplicates(inplace=True, keep=False)
covid.columns
We can use the .rename() method to rename certain or all columns via a dict.
covid.rename(columns={
'Province/State': 'Province',
'Country/Region': 'Country'
}, inplace=True)
covid.columns
Missing values
When exploring data, you’ll most likely encounter missing or null values, which are essentially placeholders for non-existent values. Most commonly you'll see Python's None or NumPy's np.nan, each of which are handled differently in some situations. We can use isnull() to check for missing values in our DataFrame.
covid.isnull()
covid.dropna()
This operation will delete any row with at least a single null value, but it will return a new DataFrame without altering the original one. You could specify inplace=True in this method as well.
covid.dropna(inplace=True)
covid.shape
Other than just dropping rows, you can also drop columns with null values by setting axis=1.
covid.dropna(axis=1,inplace=True)
covid.shape
covid['1/22/20'].describe()